Outliers refer to data: an example that differs significantly from other examples. Edge cases refer to performance: an example where a model performs significantly worse than other examples.
An outlier can cause a model to perform unusually poorly, which makes it an edge case. However, not all outliers are edge cases. For example, a person jaywalking on a highway is an outlier, but it’s not an edge case if your self-driving car can accurately detect that person and decide on a motion response appropriately.
degenerate feedback loops
created when a system’s outputs are used to generate the system’s future inputs, which, in turn, influence the system’s future outputs.
especially common in tasks with natural labels from users, such as recommender systems and ads click-through-rate prediction: “exposure bias", “popularity bias”, “filter bubbles”
Monitoring & Observability
Monitoring
= the act of tracking, measuring, and logging different metrics that can help us determine when something goes wrong
Metrics
operational metrics: the metrics that should be monitored with any software systems such as
latency
throughput
CPU utilization
server load
input metrics
average input length
average input volume
number of missing values
average image brightness
output metrics
times return Null
times user redoes search
times user switches to typing
ML-specific metrics
monitoring accuracy-related metrics
monitoring predictions
monitoring features
monitoring raw inputs
Tips
Always think about how quickly do metrics change in your data!
For example, user data generally change slowly, but B2B data can change really fast!
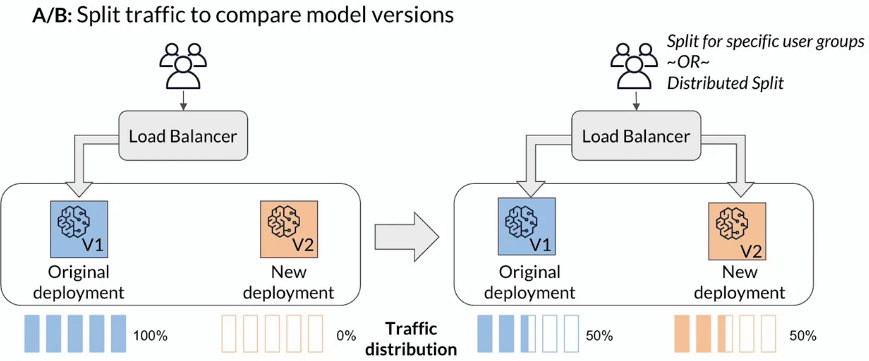
Deploy the candidate model alongside the existing model.
A percentage of traffic is routed to the new model for predictions; the rest is routed to the existing model for predictions.
Monitor and analyze the predictions and user feedback, and do stats test if any difference in prediction within long validation cycles
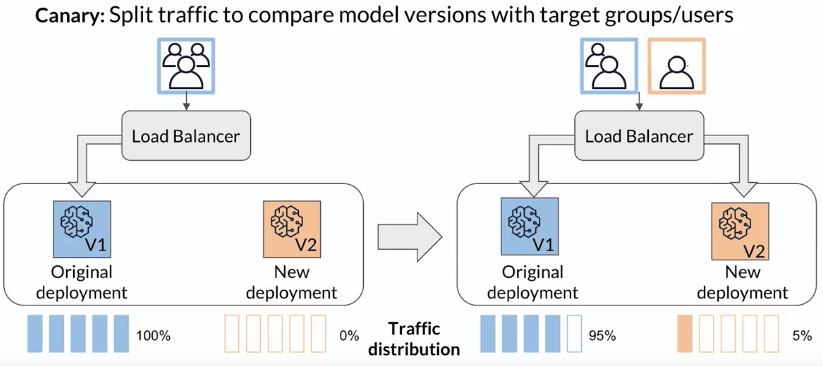
Canary release
Deploy the candidate model alongside the existing model. The candidate model is called the canary.
A portion of the traffic is routed to the candidate model.
If its performance is satisfactory, increase the traffic to the candidate model. If not, abort the canary and route all the traffic back to the existing model.
Stop when either the canary serves all the traffic (the candidate model has replaced the existing model) or when the canary is aborted.
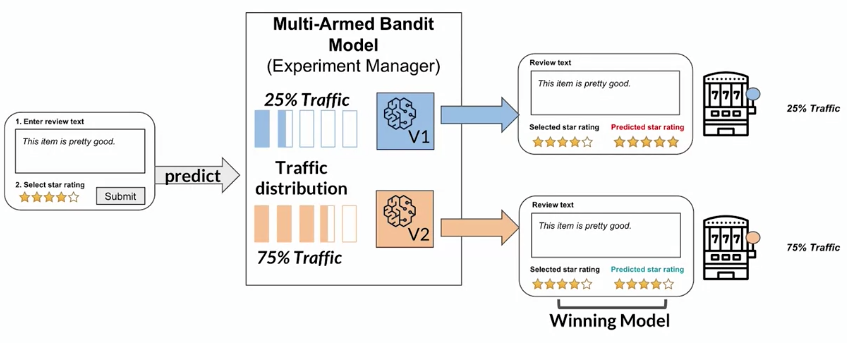
Interleaving experiments
Multi-Armed Bandits
different other static approaches, it is a dynamic approach = it tests model versions using reinforcement learning